Self Improving Skills
Automatically improve your workspace skills
Overview
Self-improving skills is a feature that automatically analyzes how users make use of skills in their conversations, and surfaces targeted suggestions to improve the skills over time. Rather than requiring builders to manually review feedback and update agents themselves, Dust does the heavy lifting: it periodically processes conversations, identifies patterns in what worked and what didn't, and proposes concrete, evidence-based edits to your skill's instructions and configuration. The goal is to accelerate the feedback loop between usage and improvement, making skills better without adding burden to builders.
How It Works
The Self-improving skills process follows the following steps:
- Nightly analysis: Every night, Dust analyzes user conversations that make use of skills. It looks at explicit signals (thumbs up/down feedback left by users) as well as implicit ones: a user correcting the agent's output, a tool that failed to be invoked when it should have been, a conversation that went off track. All of this is used to build a picture of where skills are falling short.
- Suggestions: Based on this analysis, Dust surfaces targeted improvement suggestions directly to skill builders. These can include better instructions, adjustments to existing tools, or new tools to add to the skill.
- Review: The skill’s editors review each suggestion and choose to accept or reject it. Nothing is applied to your skill without your explicit approval.
Reviewing Suggestions
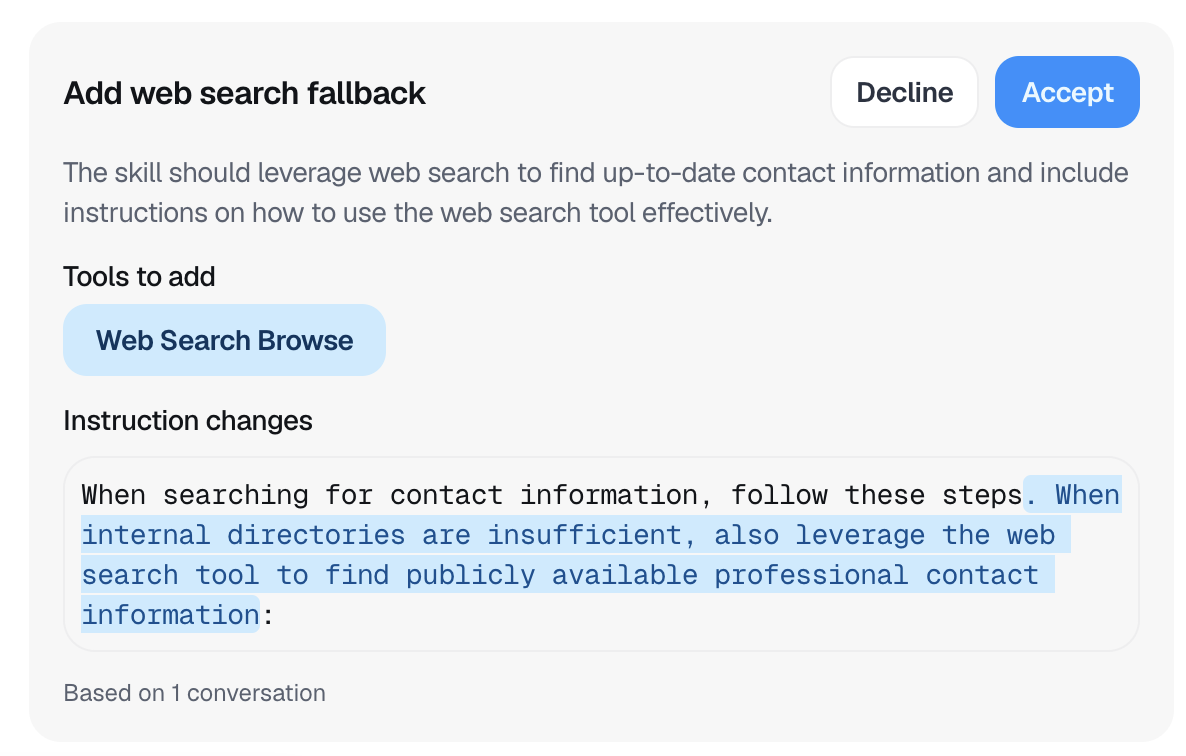
Suggestions appear in the Skill Builder's right pane as syntax-highlighted diffs. For each suggestion, you can:
- Approve: Apply the change to your skill immediately
- Decline: Dismiss the suggestion
Controlling the Feature
This feature is entirely optional.
Workspace level enablement
Self-improving skills can be disabled entirely for a workspace from the workspace settings. When disabled, no conversation analysis is performed and no suggestions are generated.
Skill level enablement
Each skill has its own toggle to enable or disable self-improvement independently. This lets you opt specific skills in or out without affecting others in the workspace.
Pricing
Self-improving skills usage is billed on your credits pool like programmatic usage.
Self-improving skills uses LLM Batch Mode to process conversations nightly. Rather than calling model APIs in real time, analysis runs through asynchronous batch APIs offered by providers (Anthropic, OpenAI, Google, Mistral), which come at a 50% discount compared to standard synchronous endpoints. These savings are passed directly to you: Self-improvement analysis is billed at half the cost of equivalent real-time API calls.
Privacy and Data Usage
What data is used and how
Conversation content is processed using the LLM provider(s) already configured and approved in your Dust workspace. Self-improving skills does not introduce any additional model providers or data sub-processors.
The following data is used:
- Conversation transcripts (messages, tool calls, and agent responses)
- User feedback (thumbs up/down and written comments)
- Current skill configurations (instructions, tools)
Customer Instruction
By enabling Self-improving skills, Customer instructs Dust to process such data as Data Processor under the Data Processing Addendum for the purpose of providing self-improving skills for Customer's own workspace. Customer confirms that it has identified an appropriate GDPR lawful basis for this processing, has provided required notices to relevant users, and has obtained any required authorisation.
No model training
Dust does not train any model or fine-tune any foundation model based on your conversations. Self-improving Skills only uses conversations to improve the instructions and configuration of your own skills.
Data isolation
There is no cross-workspace data sharing
Conversations from your workspace are only used to improve skills within your workspace. Nothing is shared across workspaces or used for any other purpose.
Data retention
Resulting suggestions and analysis summaries are stored within Dust infrastructure, scoped to your workspace, and subject to the same data governance policies that apply to all your Dust data.
Processing modes and Zero Data Retention (ZDR)
Self-improving skills support two processing modes, which have different implications for Zero Data Retention (ZDR):
Batch mode (default)
By default, self-improving skills use LLM Batch Mode to process conversations nightly. Batch APIs are not covered by ZDR guarantees from any of the supported providers (Anthropic, OpenAI...). This is by design of batch processing: batch results must be temporarily stored server-side until they are processed and Dust retrieves them. To minimize exposure, Dust immediately deletes batch data from the provider after downloading results.
In practice, this is not different than a normal conversation, except that the conversations can take up to 24 hours to be processed by the LLM providers.
Streaming mode (ZDR-eligible)
Workspace admins can disable batch mode independently from the self-improving skills feature itself, in workspace settings. When batch mode is disabled, self-improving skills process conversations using synchronous streaming calls, which are covered by ZDR guarantees. Note that streaming mode is more expensive than batch mode.
If your workspace has a strict ZDR requirement, you should either disable batch mode in your workspace settings (to keep self-improving skills active but ZDR-compliant) or disable self-improving skills entirely.
Updated 18 days ago