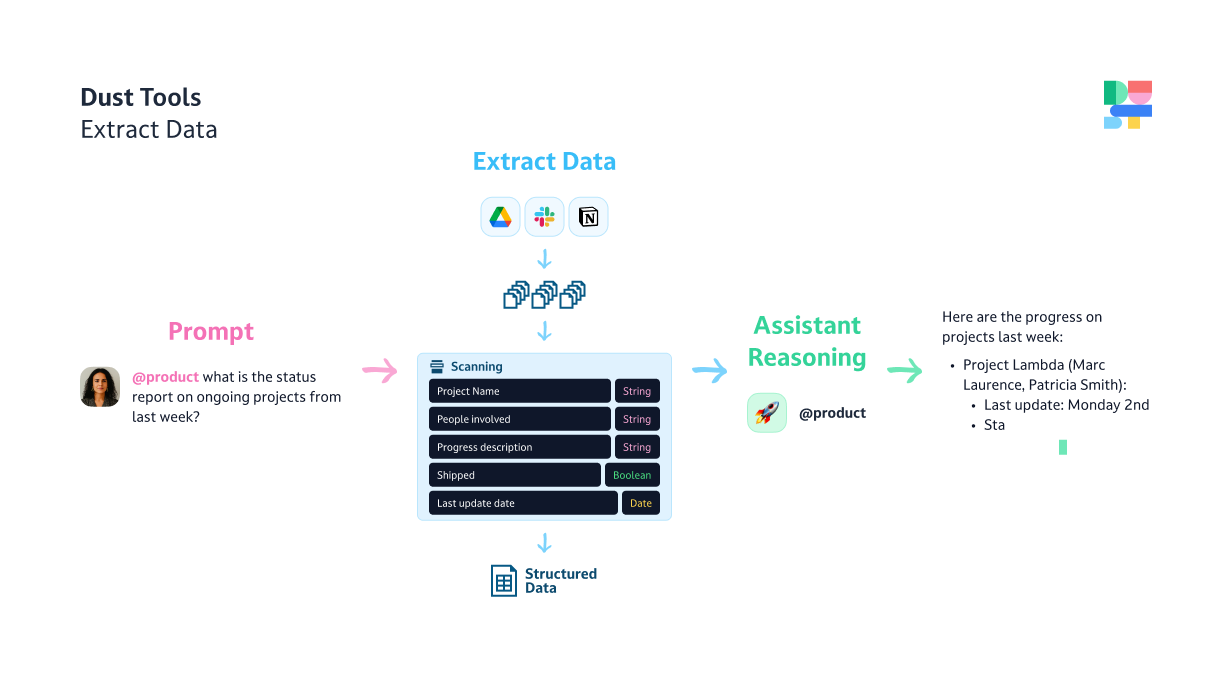
Extract data
Extract data from unstructured sources in a structured manner and feed it to LLMs
Overview
The Extract Data action enables agents to extract structured information from a large window of data coming from your data sources over a specified time frame.
A large language model is run on up to 500k tokens (1000 pages book) and emits structured pieces of information following a schema of your design.
This can be used to:
- Generate daily or weekly highlights from Mailing lists
- Extract quantitative data from a stream of unstructured interactions such as customer support tickets.
This comes as a complement to the “Search” and “Most Recent Data” actions:
- The “Search” action perform semantic search and does not provide guarantee that the entire data is processed by the agent and cannot extract information in a structured manner according to a custom schema definition.
- The “Most Recent Data” is limited by the context size of the model and won’t be able to process large amount of data from data sources and is generally meant for low volumes of recent information.
The output of the Extract Data action is a list of objects following the schema definition you configured which is passed to the agent to answer your question.
Configuring the Extract Data action consists of the following steps:
- Configure the data sources you want to process
Optionally, you can configure the following advanced settings:
- Select a time frame
- Define or generate a schema to extract
Configure the Extract Data action
Configure the Data Sources to Process
This is very similar to the “Search” action. Select a data source you want to process. Generally a Slack channel, a Folder you feed by API or Intercom tickets.
Advanced Settings
The Extract Data action includes advanced configuration options that can be accessed through a collapsible section:

Select a Time Frame
By default, the time frame is determined automatically based on the conversation context. You can enable manual time frame selection when you need to specify an exact range for data extraction.

Define or Generate a Schema to Extract
Optionally, you can define the schema used by the large language model to extract pieces of information from the data sources. The schema uses JSON Schema format to define the structure of extracted information. You can:
- Define the schema manually by entering your JSON schema definition directly
- Get your schema generated automatically by an agent based on your instructions by clicking on "Generate". The generated JSON schema can be edited.
If you do not specify a schema, the tool will determine the schema based on the conversation context.
Using an Agent based on Extract Data
Using an agent based on Extract Data is similar to any other agent. These agents being generally thoroughly prompted you often only need to call them.
Given the intensive work involved with the Extract Data action, expect their execution to take more time than usual.
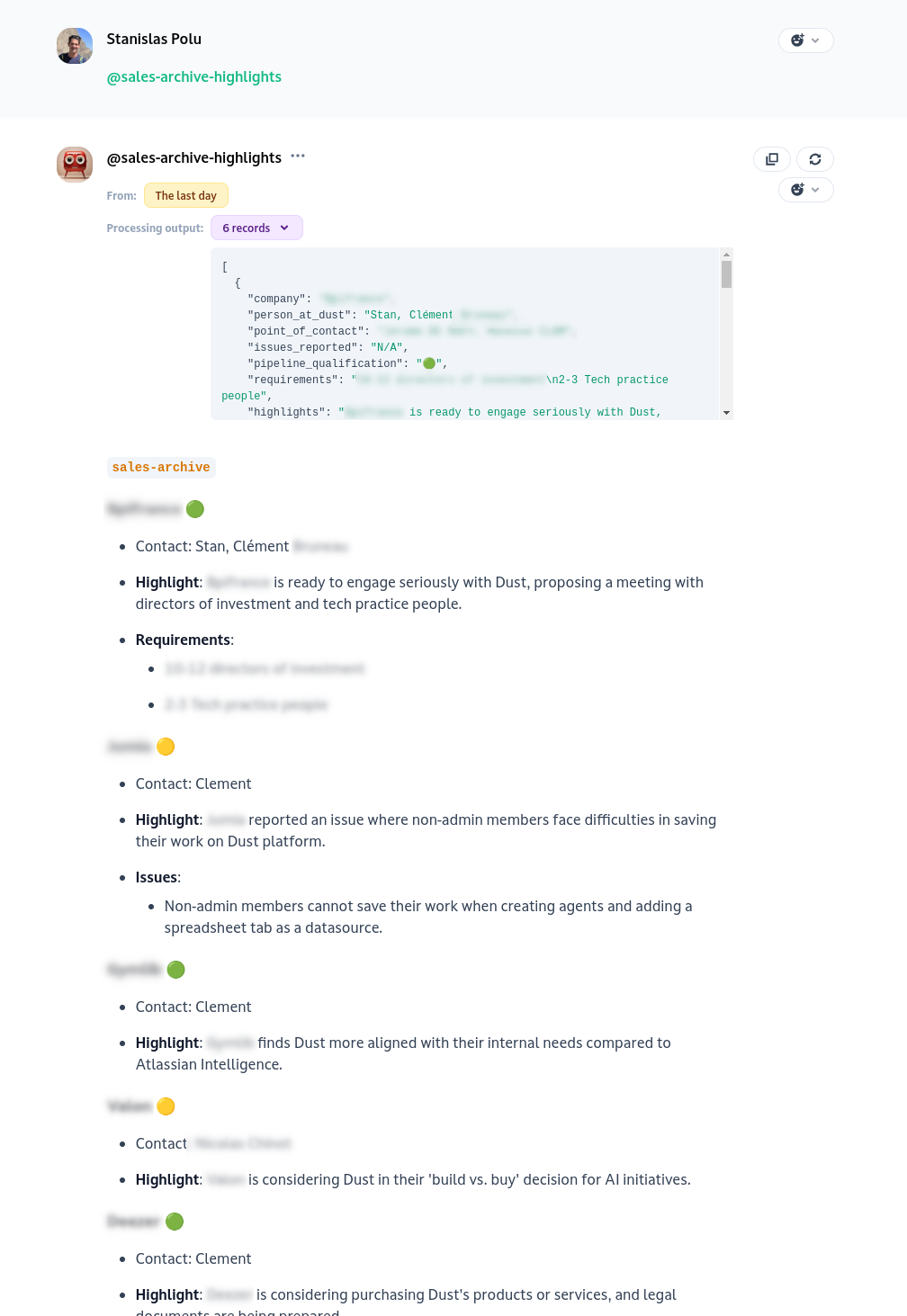
The output presented to the agent to generate the answer can be introspected. As an example, the instructions of the agent above (with the schema visible in the screenshots of the previous section) are the following:
Context: Dust (the company that owns that list) is a platform to build custom and safe agents on top of their users' company data (Notion, Slack, Gdrive, ....). Agents can be easily packaged by users on top of their company data and interacted with through a conversational interface.
Highlights have been extracted from emails on our internal mailing list "sales-archive" which is used to cc internally emails related to our sales efforts.
Based on these highlights generate a structured summary of all the interactions. Avoid broad statement or general facts. Be extremely concise and brief this content is targeted at internal employees of Dust who want to save time and get the information rapidly without reading all the emails.
If there is multiple interactions for the same company, merge them together. If an interaction has company "N/A", use "Dust Internal" as company name.
### `sales-archive` {{ FOREACH company }} #### {{Company Name}} {{pipeline_qualification}} - Contact: {{Dust point of contact}} - **Highlight**: {{1 sentence highlight}} {{IF there are issues}} - **Issues**: (if any) - {{ list of issues}} {{ENDIF}} {{IF there are requirements}} - **Requirements**: (if any) - {{ list of requirements}} {{ENDIF}} {{ ENDFOR company }}
Updated 10 months ago