Search data sources
With Dust, you can ask your agents to search through your entire selected Data Sources and pick the most relevant documents to tap into to answer. Dust provides RAG capabilities and agents are able to search your data semantically before sending your message to the chosen model (cf. Understanding Retrieval Augmented Generation (RAG) in Dust).
To be able to use this, you need to have created some Datasources first - Connections, Folders and/or websites.
You will then need to select from your data sources exactly what you want this agent to be able to search from. This means any of your Connections, Folders or Websites and you can even pick sub-pages or specific channels.
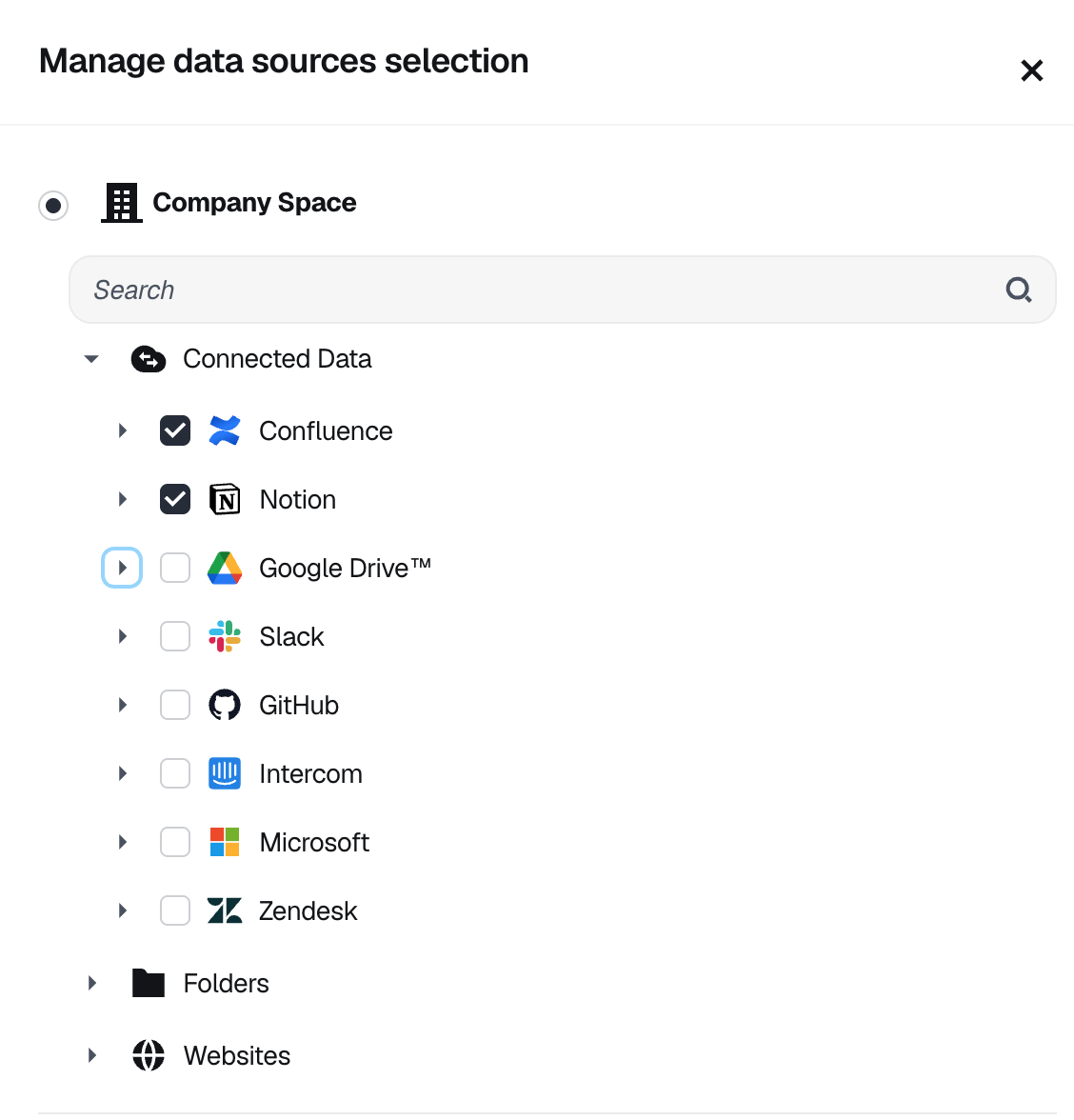
Pick from any of your data sources

Once you've picked a data source, you can fine-tune the pages available to your agent
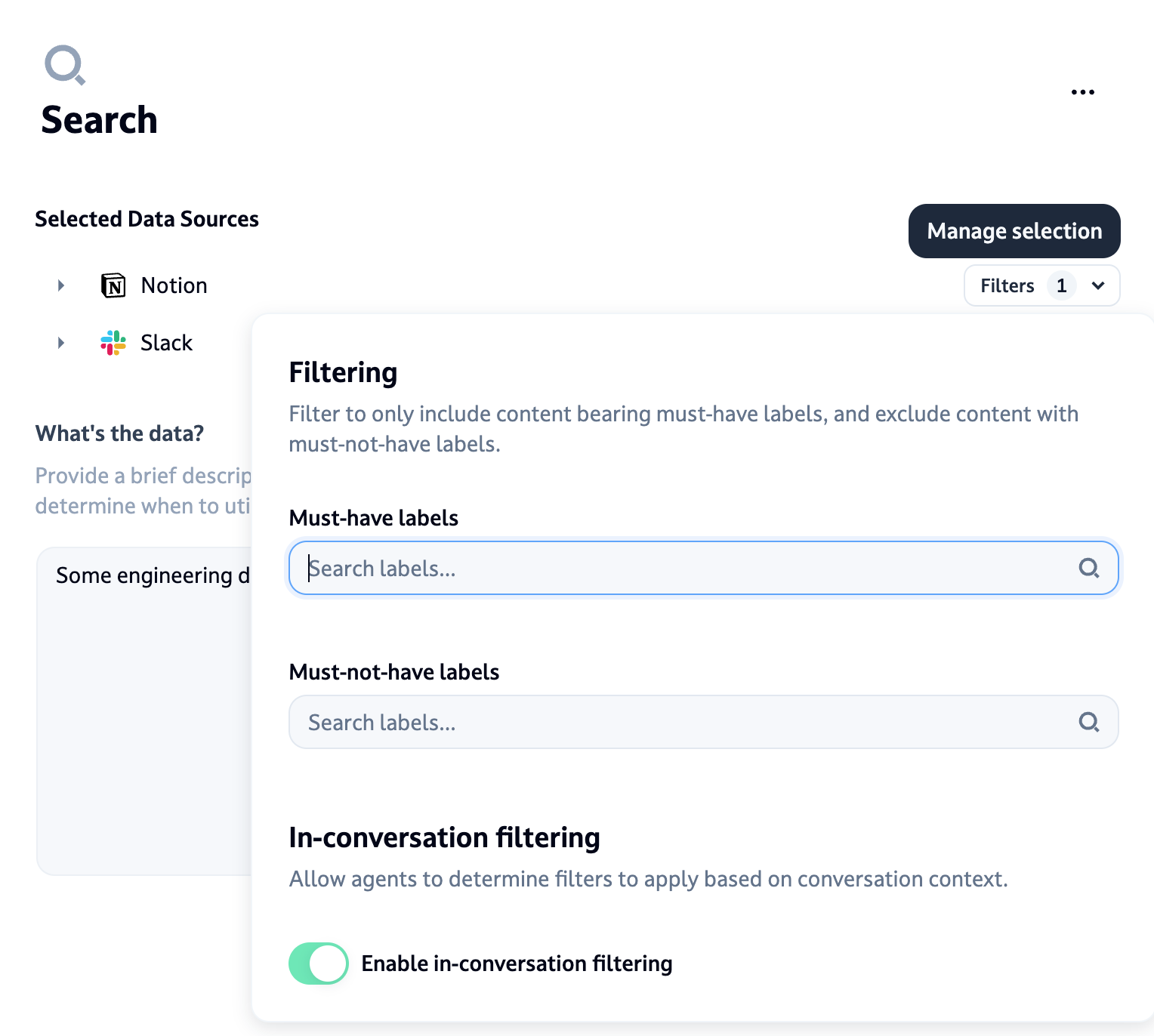
Additional filtering with labels
After selecting your data sources, you can apply additional filtering using labels to refine what content is available to your agent:
- Exclude specific content : Filter out pages with certain labels (e.g., "deprecated").
- Include specific content : Only include pages with specific labels (e.g., from a particular author).
- In-conversation filtering : Enable dynamic filtering based on conversation context. This requires exact tag matching. For example, you could ask "What projects currently have the label 'status:review'?".
The filtering system works with the following logic:
- Documents must have at least one of the "must-have" labels to be included (including those determined from in-conversation filtering).
- Documents with any "must-not-have" labels will be excluded (including those determined from in-conversation filtering).
NoteLabels are supported on Folders and on most of our Connections (see "Labels" section on the Connections pages of our documentation).
Searching my data, how exactly?
When this method is activated, the agent will search your data for the right information by understanding the context of the user's question. This is possible through a process called Semantic search.
Semantic searchSemantic search in RAG is a method for finding relevant information based on meaning and context, not just keywords. It uses advanced techniques like embeddings and similarity measures to understand query intent and retrieve contextually appropriate information from a knowledge base. This enhances RAG models' ability to generate more accurate and informed responses by augmenting the language model with pertinent, up-to-date information.
Let’s take an example:
Imagine you are creating an agent whose goal is to expose HR documentation to your employees. They can search for anything regarding their holidays (PTO), hiring policies, parental leave, etc. They already have access to your documentation (Confluence, Notion, etc.) but this information is lost somewhere in a sea of articles and a lot of them can't find it easily. The agent will:
- Understand the user question (e.g. "what should I prepare for a parental leave?") and search for the right articles and the right chunks inside of the articles that will actually have the answer.
- It will then feed this content to the model with the full query of the user.
- The model will will generate a response to the user's question, taking into account the results from the data source and giving the links to the right sources.
Advanced search mode
Advanced search mode can be enabled in the agent builder under Search > Advanced settings. When enabled, agents gain filesystem-level access to your data sources in addition to semantic search.
How it works: Agents can list folders, browse directory structures, and read specific files by their exact path, treating data sources like a file system. This complements semantic search by allowing agents to navigate your data organization directly.
- Direct access to specific files by name or path
- Ability to explore folder hierarchies and understand data organization
- Useful for structured data where folder organization provides context
- Works alongside semantic search for more flexible data access
- Generally requires more tool calls, hence more induced latency, to locate and retrieve information
Enable Advanced search mode when your data sources have meaningful folder structures that agents can leverage, or when agents benefit from accessing complete documents.
When should I use the Search option?
Search option?This method is particularly useful in scenarios where the data might be coming from data sources that you have synced with Dust: Google drive, Confluence, Notion, Slack, etc.
Granularity
While it is tempting to add all of your data sources to an agent, it is not always the right choice! (And you can already query all of your data sources using the @dust agent if your workspace is configured with it.
LLMs perform best when provided with the right data. So agents that are plugged to a constrained number of data will usually perform better than the ones with access to everything.
And remember when creating an agent, try different options to evaluate which one suits you best!