Include data
With Dust, you can ask your agents to search through your entire selected Data Sources and pick the most relevant documents to tap into to answer. This is the “Search” tool (cf. Understanding Retrieval Augmented Generation (RAG) in Dust)
But sometimes, there are specific files or pieces of context you want to be sure that the agent includes in its context window for every question (i.e. a translation glossary or a set of guidelines that must be followed). The Include Data tool gives you the ability to dictate that the agent always includes a set of files. Starting with the most recent file, the agent will take into account every document set in Include Data in chronological order (assuming they don't fill the context window of the agent)
Note: While very useful when you need particular documents to be included, LLMs are quite effective at finding relevant context across a large knowledge base using the Search Tool, which tends to be a better fit for larger data sources (see below for use-cases with Include Data).
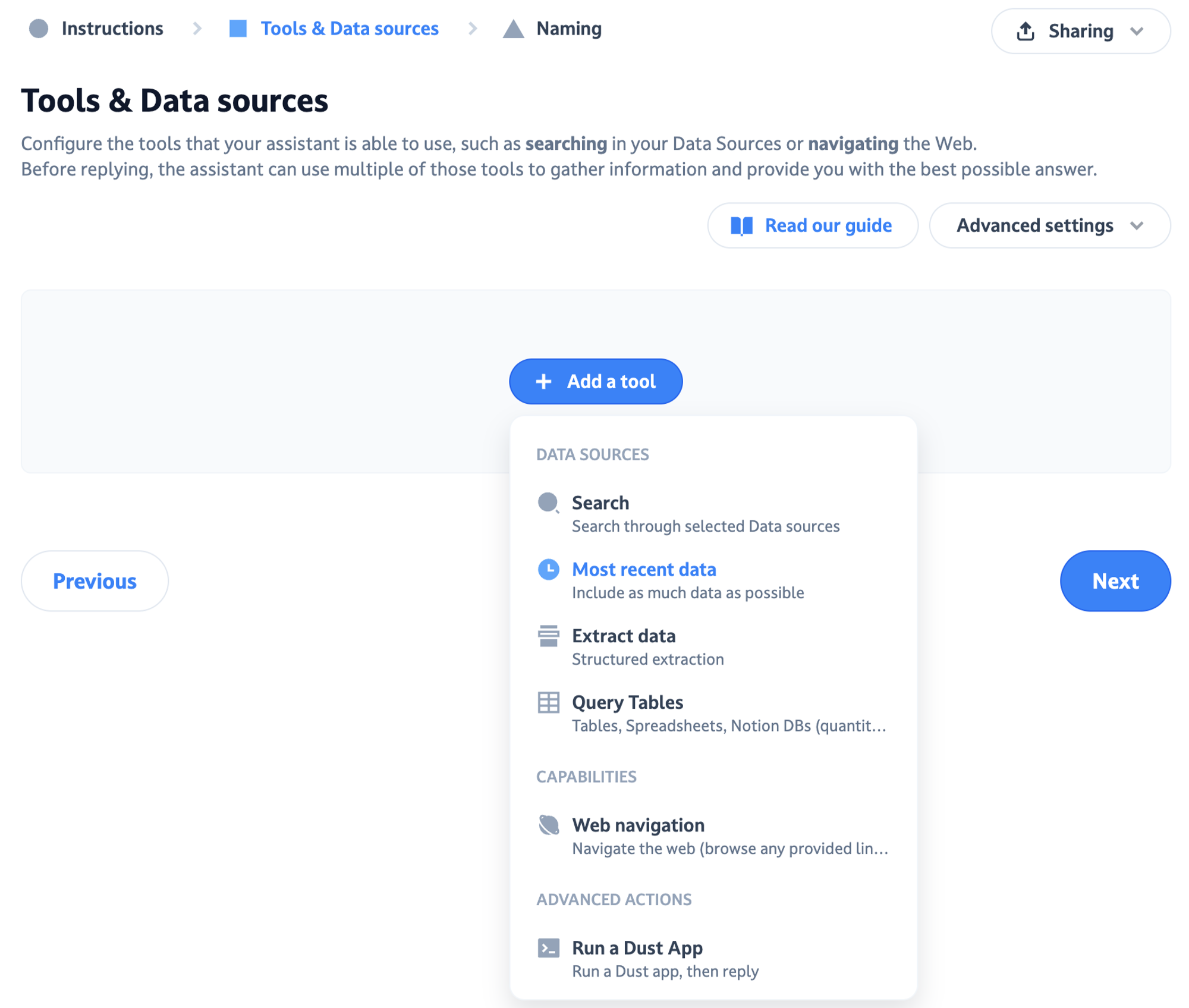
Here's how it works:
Takes only most recent data into account…what does this mean?
When this method is activated, the agents retrieves all latest documents from your data source in reverse chronological order, until your agent context window is filled.
Let’s take an example:
Imagine you are creating an agent whose data source is a Google Drive folder. This is how the agents will gather information to generate answers to your questions:
- It will look at the folder, and pick the latest file
- Then it will pick the file updated just before, then the previous one, etc. without filtering anything out
- It will continue until it reaches the limit of what it can process at once (the method’s context window*).
- Finally, it will generate a response to the question you asked, taking into account only the files picked in the 3 previous steps
Side note: to smooth product experience, Dust sets its own specific context window for “include data”. So it does not exactly correspond to the context windows of agents’ underlying models.***
When should I use the ‘include data’ option?
This method is particularly useful in scenarios where the most current information is crucial: news monitoring, project updates, or any area where exhaustivity and recent developments are more relevant than older information.
Example again:
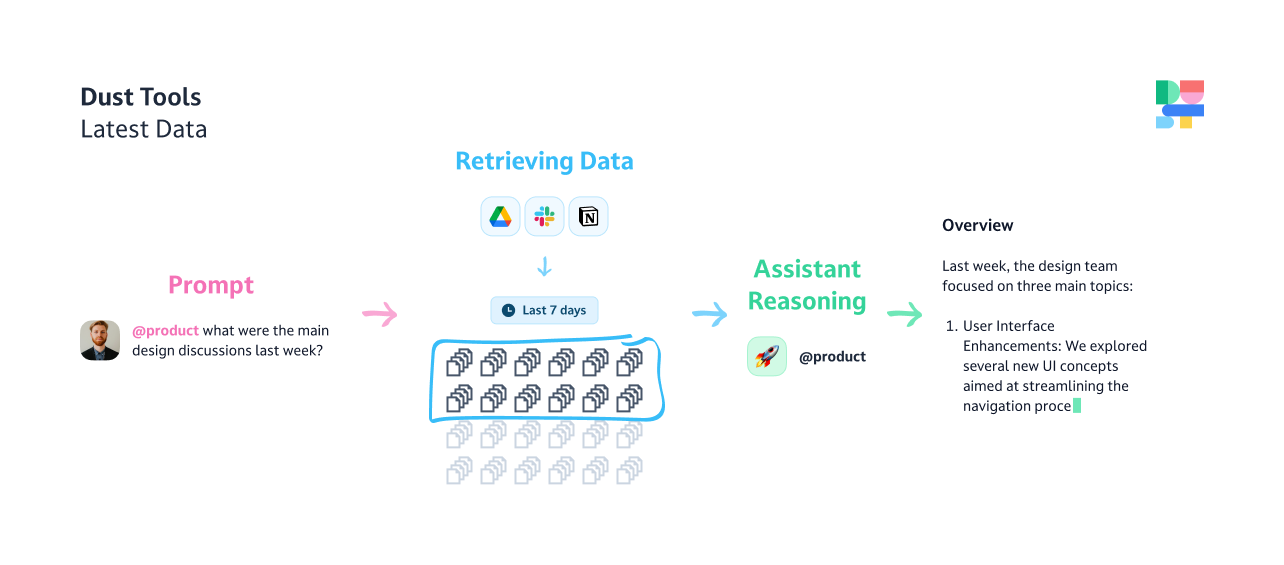
At Dust, we use Include Data to track recent features shipment.
- Every time something is shipped in the product, the responsible team member sends a message in #shipped, explaining what is new and why we shipped it.
- Then we use our @WeeklyShipped agent to create a synthesized table and update the whole team with a short and crisp snapshot every week.
Limitations
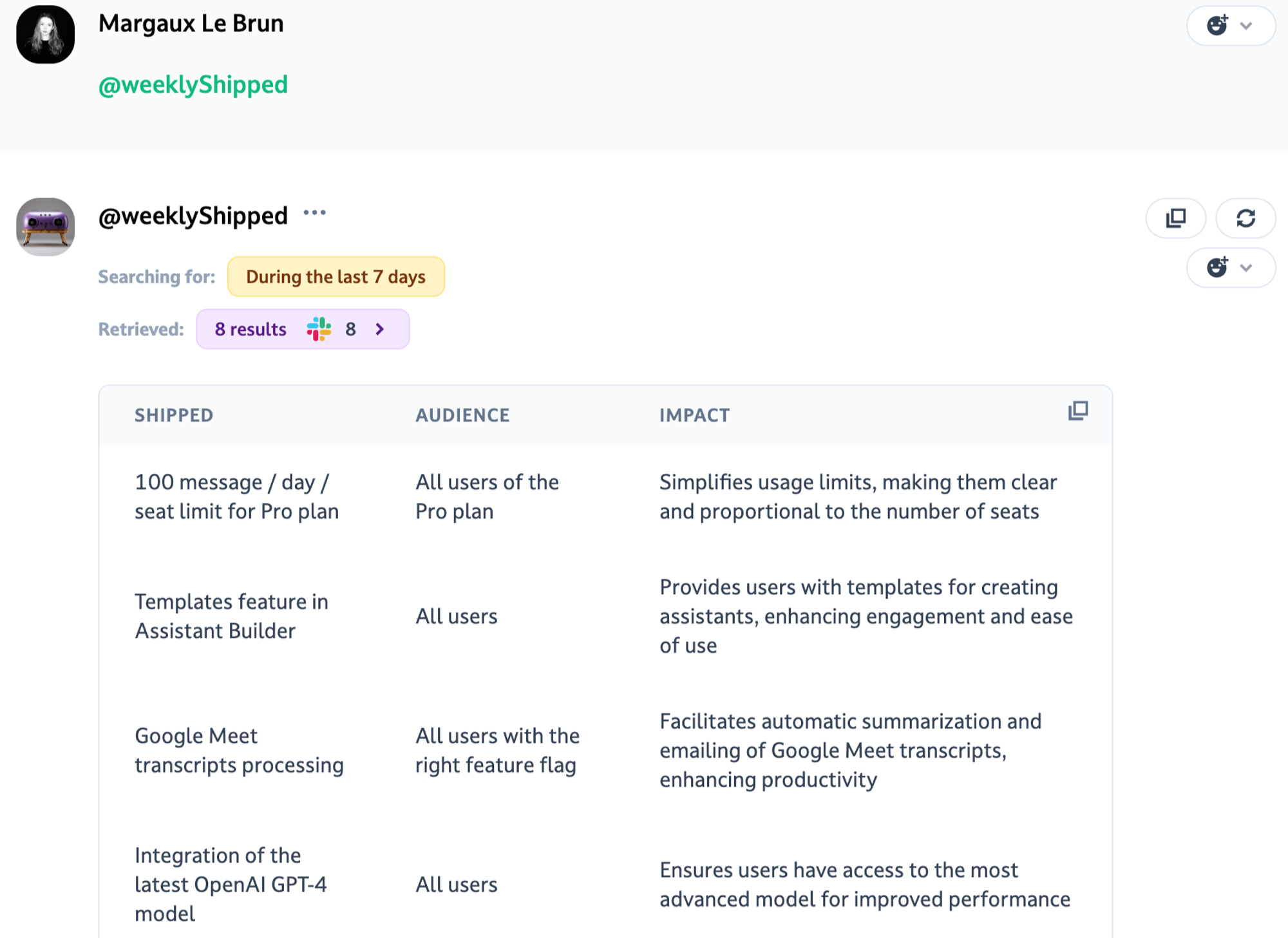
- While this method ensures that the most recent documents are considered first, it does not prioritize the relevance of the content based on the query beyond recency: it takes ALL recent data, without any filter. Therefore, it might not always return the most contextually relevant documents if they are older than the most recent ones.
- The context window can be limiting: depending on the model used and the volume of data you have, you might not be able to retrieve data from a large period of time.
In the example below for instance, the “warning” box indicates you cannot go further than a certain date:
When you create an agent, try different options to check which one suits you best!