Understanding Retrieval Augmented Generation
As you explore Dust's capabilities, you'll see you can create various types of AI agents, each designed to help you access and understand your data in different ways.
One of the most powerful is the Retrieval Augmented Generation (RAG) agent, which uses semantic search to find relevant information and generate answers to your questions.
You create this type of agent when you use the Search action.
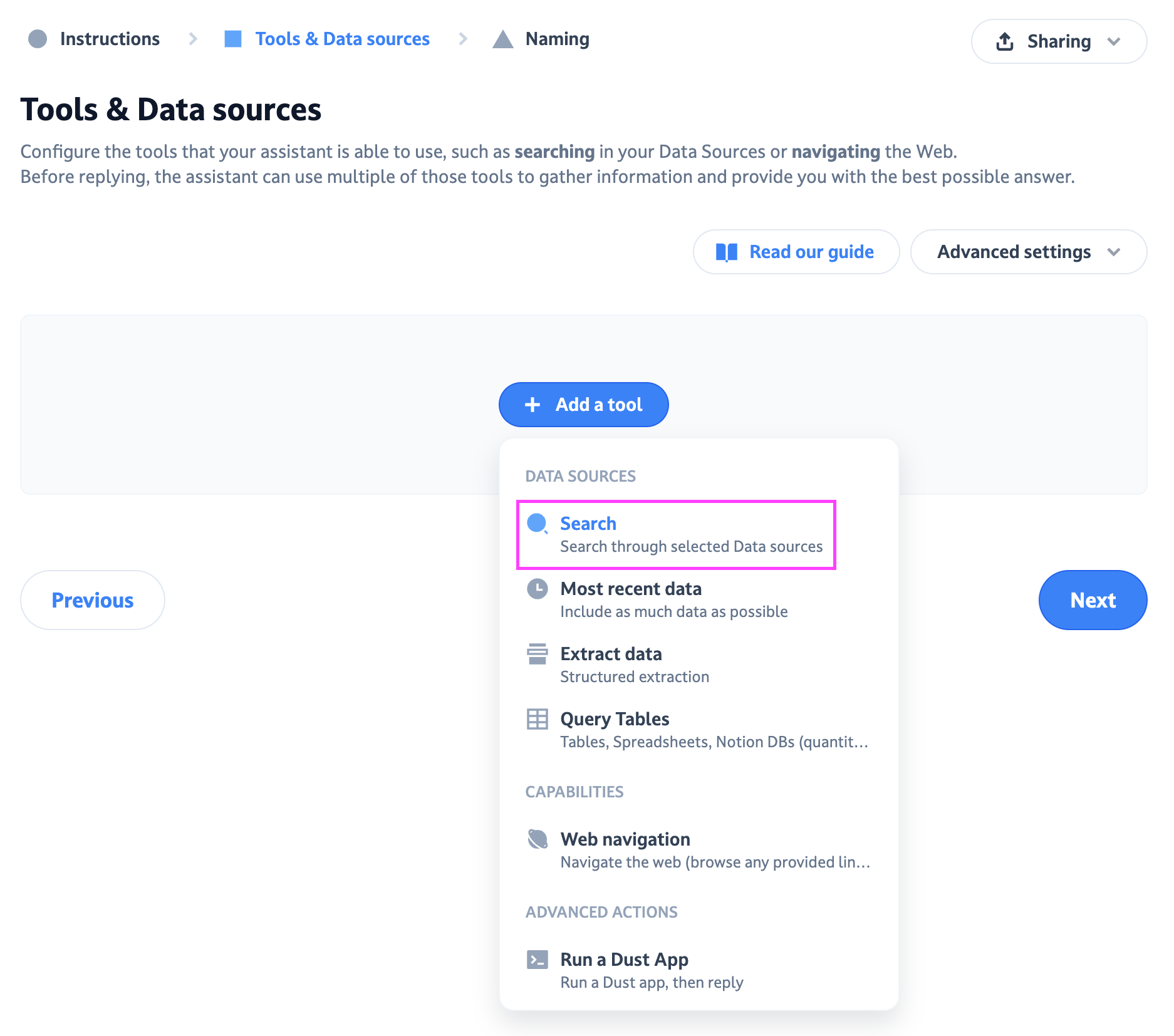
In this guide, we'll dive into how RAG works, its strengths and limitations, and how you can effectively leverage it in Dust.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation, or RAG, is a powerful technology that combines the capabilities of large language models (LLMs) with an extensive knowledge base. It's like having a personal researcher who can:
- quickly scan through a vast library of documents,
- find the most relevant pieces of information,
- and synthesize them into a coherent answer.
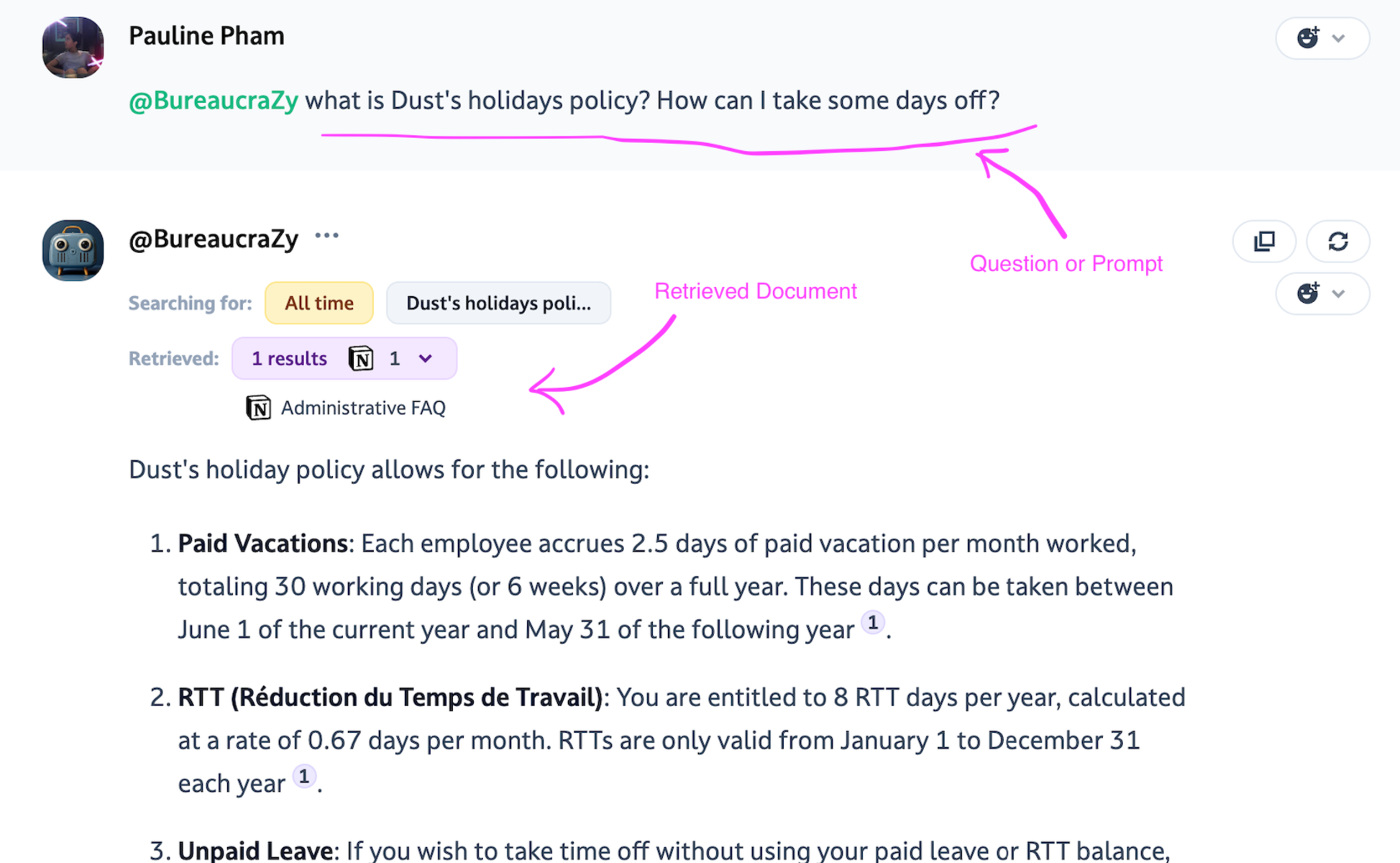
Here's a step-by-step breakdown of what happens when you ask a question to a RAG agent in Dust:
-
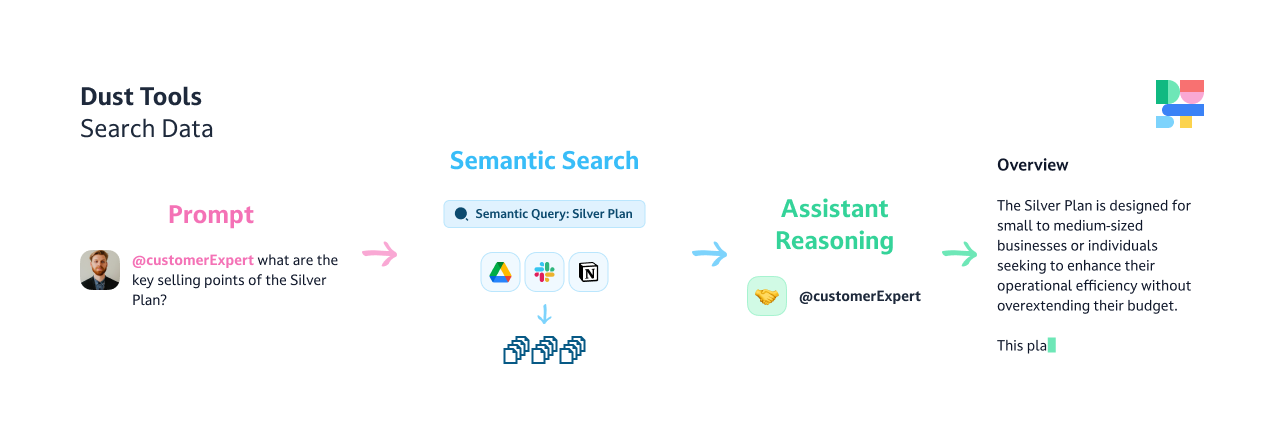
Semantic Search: Your question or prompt acts as a search query, looking for semantically related information in your connected data sources. Your agent uses advanced techniques to understand the meaning and context of your question, not just the keywords.
-
Document Retrieval: Based on the semantic search, the agent retrieves a set of documents that are most likely to contain the information needed to answer your question. This is like pulling relevant books off the library shelf.
-
LLM Processing: The retrieved documents, along with your original question and your agent's instructions, are fed into the large language model (LLM) you selected. The LLM uses its understanding of language + the context you provided in the prompt + the instruction to analyze the information and generate a response.
-
Answer Generation: The LLM synthesizes an answer based on the retrieved information, aiming to provide a clear and comprehensive response to your question.
The power of RAG lies in its ability to access a vast amount of information without needing to store it all within the model itself. By combining semantic search with the generative capabilities of LLMs, RAG can provide informed, context-aware answers to a wide range of questions.
The Detective Metaphor
Imagine you're a detective with access to a vast archive of case files.
You need specific information to solve a case but can’t go through all files manually. RAG acts like your investigative partner who scans relevant files quickly and briefs you on the most pertinent information.
Here is a visual recap:
Why It Doesn't Answer "How Many?"
Semantic search is about depth, not breadth. It dives deep into topics to fetch relevant information but doesn’t tally up occurrences or keep track of total document counts.
Your RAG agents will struggle with questions that require precise numerical answers, such as
"How many documents discuss topic X?"
or
“How many documents do you have access to?”
Here’s why:
Strengths and Limitations of RAG
While RAG is a powerful technique for accessing and understanding your data, it's important to be aware of its strengths and limitations:
💪 Strengths:
- Accesses a large knowledge base: RAG can draw from a vast corpus of information to provide comprehensive answers.
- Understands context: Using semantic search, RAG can find information relevant to your question's meaning and context, not just direct keyword matches.
- Generates natural language answers: The LLM component allows RAG to provide answers in clear, coherent language.
✋ Limitations:
- Selective Retrieval: RAG scans for relevance, not completeness. It picks documents that seem most useful for your query, which doesn’t necessarily cover every instance of a topic.
- Lack of Counting Capability: The system is designed to understand and generate language, not to count occurrences across documents.
- Not a replacement for structured data queries: For tasks requiring precise, quantitative answers, querying structured databases is often more effective than RAG.
Alternatives for Numeric and Structured Queries
When you need precise numbers or structured analysis, RAG might not be the best tool. Here are better-suited features in Dust:
1. Use Include Data
This method involves retrieving documents in reverse chronological order until they fill the capacity of the model’s context window based on the timeframe you set. It is like telling your agent to start with the newest documents and read backwards until they've filled a certain number of pages. This is helpful if you're more interested in recent information, but it is still not ideal for counting. Learn more in Include data
2. Table Queries
If you need to perform complex data analysis or retrieve exact counts, querying tables via Dust is your go-to method.
The "Query Tables" action lets you connect Dust to structured databases like CSVs, Google Sheets, and Notion tables. You can then ask questions that get translated into SQL queries to fetch answers. This is a more precise way to get numerical insights.
For example, if you manage customer feedback in a structured database, you can easily query how often customers mentioned a specific issue last month. Learn more in Table queries
3. Extract Data
If you need to retrieve more exhaustive data following a certain “hard coded” pattern from large sets, Extract Data is the method you should turn to. The Extract Data action enables agents to extract structured information from a large window of data coming from your data sources. You can also specify a precise time frame.
A large language model is run on up to 500k tokens (1000 pages book) and emits structured pieces of information following a schema of your design. Learn more in Extract data
Using RAG Effectively in Dust
To get the most out of the RAG agents you create in Dust, it's important to understand when and how to create/use them:
- Formulating Questions: Ask clear, specific questions that focus on the information you need. Avoid hashtags and overly broad or vague queries that may retrieve less relevant documents.
- Understanding the Output: Keep in mind that RAG provides a synthesized answer based on the retrieved documents. It's not pulling a pre-written response from the knowledge base. Be prepared for some variability in how answers are phrased.
- Iterating and Refining: If the first answer isn't quite what you were looking for, try rephrasing your prompt or providing more context in your question— or even the agent's instructions. If given more specific guidance, your RAG agent can often provide more targeted answers. Learn more in our guide: Prompting 101: How to Talk to Your Agents
- Knowing When to Use Other Tools: Use RAG for open-ended questions and Table queries for quantitative analysis. For questions that require precise, numerical answers (like "How many users mentioned Feature X last month?"), consider using Dust's structured data query tools instead of RAG. These allow you to interrogate databases and spreadsheets for specific data points directly.
Conclusion
RAG is a potent tool for synthesizing knowledge from vast information pools and answering complex questions. However, for quantitative tasks, leveraging Dust’s structured query capabilities will provide more precise and actionable data. Understanding when and how to use these tools will maximize your efficiency and effectiveness in managing information and making data-driven decisions.
Updated 4 months ago