Developer Platform overview
An overview of the Dust Developer Platform along with its associated design principles. You will learn how a Dust app is structured and how it is executed.
Dust is designed to provide a flexible framework to define and deploy large language model apps without having to write any execution code. It is specifically intended to ease:
- Working on multiple examples at the same time while designing a large language model app.
- Introspecting model outputs produced by intermediary steps of large language model apps.
- Iterating on the design of large language model apps by providing a granular and automated versioning system.
Motivation
Based on years of experience designing large language model apps, we argue that code is not the most appropriate abstraction layer when designing large language model apps.
Entanglement and Speed. When designing such apps, which generally consist in chains of calls to large language models, it is highly recommended to work on multiple examples at the same time (maybe a half-dozen) to avoid overfitting your design to one particular example. Given the latency associated with querying large language models, when working on an app with, say, 3 chained called to a model, using 6 examples at the same time, testing your app already requires 18 calls to a large language model. The first thing most developers will do is to parallelize the execution of the app, effectively entangling the logic of the app with language-specific execution code. In our experience, this has created a lot of friction while exploring the design space of an app, as each change of paradigm generally requires a refactor of the execution code already produced.
Introspection. Additionally, large language model outputs are extremely verbose. They include not only the text generated but also the probabilities of each associated token. When iterating on the design of a large language model app, especially if it has chained calls, most developers will stop logging the outputs of the model to avoid flooding their console (especially when executing in parallel). This prevents later introspection of the behavior of each element of the app.
Versioning. Finally, designing a large language model app is an extremely iterative process. It requires iterating on the prompt associated with each chained call to a large language model, as well as the overall orchestration logic. This iterative nature makes it easy to forget or fail to capture the state of an app at a given point in time. This prevents its recovery if the design exploration leads to a dead-end.
Dust intends to solve each of these pain points by introducing a block structure along with an automated caching and versioning system.
-
Entanglement and Speed: Dust's execution engine automatically takes care of executing apps blocks in a fully parallelized manner, optionally caching model interactions to increase speed of iteration. As a result, Dust apps encode their logic and nothing more, making them easier to understand and maintain.
-
Introspection: Dust automatically stores every block execution output and provides an UI to easily introspect them on-demand. We believe leveraging a UI is crucial while designing large language model apps to allow, when needed and possibly retro-actively, the introspection of each block output.
-
Versioning: Dust automatically stores each version of your app as well as each execution of it allowing you to design with confidence, knowing that it is always possible recover a previous version of your large language model app. We believe this is important given the highly iterative nature of this process.
Blocks
Dust apps are composed of blocks executed sequentially. Blocks don't have inputs, but they can refer to the output of any previously executed block.
A block has a type and a BLOCK_NAME (uppercase, no space). Each block, when executed outputs a JSON object that can later be accessed by subsequent blocks using their name.
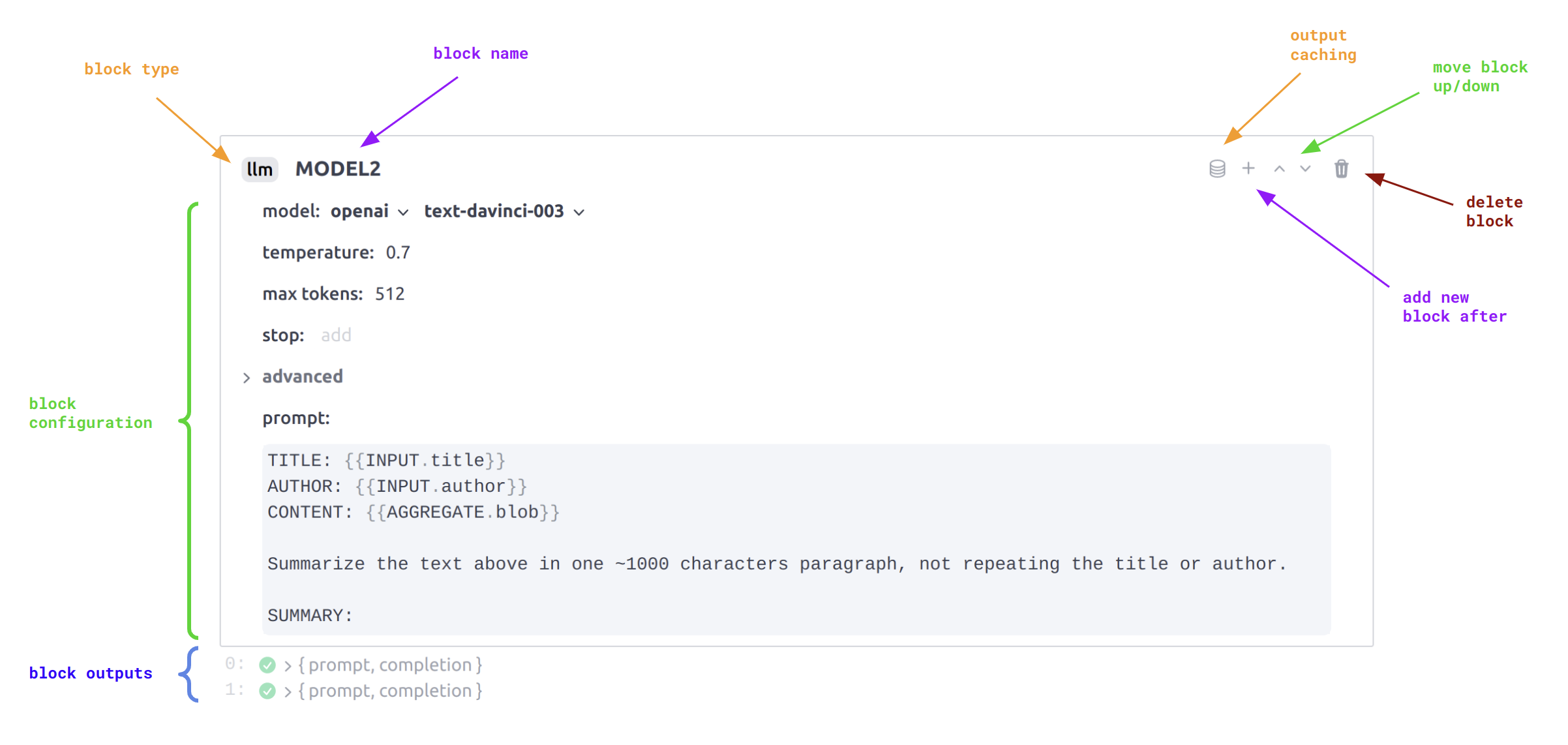
The anatomy of a Dust block showing where blocks type, name, and
configuration can be edited. Also presents the common tooling available to all
blocks. In this example INPUT.title or AGGREGATE.blob refer to previous
blocks outputs, respectively the title and blob fields of the INPUT and
AGGREGATE blocks output objects.
Each block has a set of specification arguments and configuration arguments. The specification
arguments are arguments that are not meant to be changed from one execution to the other. The
configuration arguments are arguments that can be changed from one execution to the other. The
distinction between the two is somewhat arbitrary and guided by the motivation of being able to run
an app with various configurations. As an example, this can be used to evaluate the performance of
different models. To illustrate the distinction, the llm block's prompt is part of its
specification whereas the model is part of its configuration.
The Dust Developer Platform UI does not explicitly expose the distinction. But you can arbitrarily change the configuration of each blocks of an app each time you call it by API.
Inputs
The input block is the block that receives the arguments required to run a Dust app.
By default, a Dust app has a unique execution stream, but the input block allows you to run a
Dust app on multiple inputs in parallel while designing it. During the design phase, an input
block refers to a dataset, and when executed, will fork the execution stream on each element of its
dataset and return that element as output. After an input block, each block will have as many
outputs as there are elements in the dataset associated with the input block, representing the
outputs for each parallel execution stream.
There can be only one input block per app. Before the input block there is only one stream of
execution. After the input block, there is as many parallel streams of execution as there are
elements in the dataset associated with the input block.
The input block is used to parametrize an app's behavior. While designing
the app, it is associated to a dataset of input examples. When the app is run
by API, it will return the inputs passed by API.
When run by API, an app receives an array of inputs (generally just one, but multiple is possible) and will be executed on these inputs instead of the dataset it is associated with during the design phase.
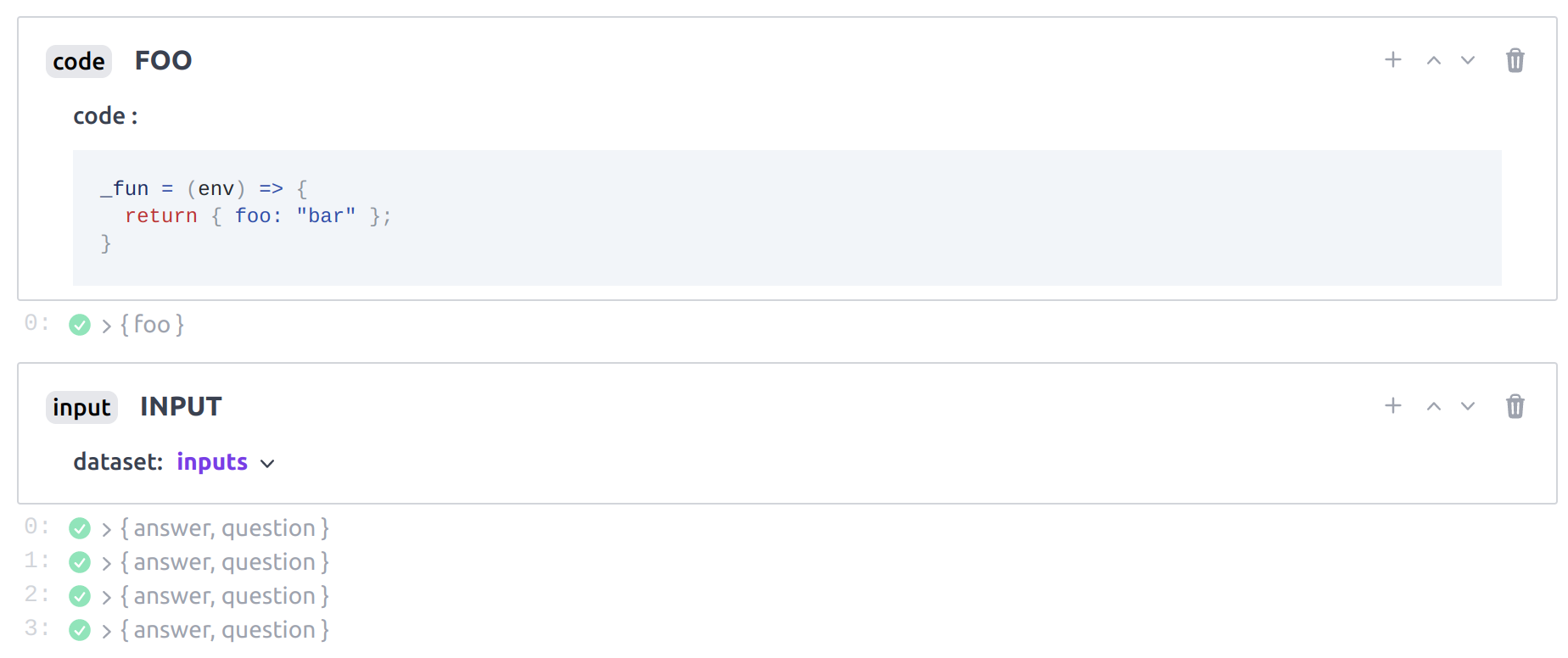
_The code block FOO is executed only once and its output will be
accessible from each stream of execution spawned by the input block. The
outputs of the input block are elements of the dataset it is associated
with, one element per stream of execution. Subsequent blocks will have access
to outputs from their respective streams of execution.
Datasets
Dust apps can also define datasets which are arrays of JSON objects. Datasets' main roles are to:
- Store example inputs on which the app is run during its design. These datasets are pulled from
inputblocks. - Store few-shot examples used when prompting models. These datasets are made available to
llmblocks through the use ofdatablocks (see core blocks).
All datasets are automatically versioned and each app version points to their specific dataset version.
Execution
The Dust execution engine will run an app in parallel on each element attached to the input block.
Each input's execution trace is completely independent and these cannot be cross-referenced. Previous
runs of an app are stored along with the app version and all the associated block outputs. They can
be retrieved from the Runs panel.
Other core blocks allow the further parallelization of the execution such as the map and
reduce blocks. Dust's execution engine will also take care of automatically parallelizing
execution eagearly when they are used.
Data sources
Data sources are fully managed semantically searchable databases of documents. You can easily create Data Sources and add documents to them manually in the Dust interface or using our API. Data sources enable apps to perform semantic searches over large collections of documents, only retrieving the chunks of information that are the most relevant to the app's task.
Semantic search, generally based on embedding models, is important to large language model apps because of the limited context size of models. It enables the retrieval of chunks of valuable information that can then be fit in context to perform a particular task. This is called retrieval-augmented generation.
Typically, to perform semantic search, one has to chunk, embed and index the documents they desire
to make them searchable from a vector database. When answering a query they then have to embed the
query, perform a search in the vector database and retrieve the associated documents and relevant
chunks of text. Dust simplifies this process by providing a Data Source abstraction that allows you
to simply upload documents and query them from the associated data_source block.