Introduction
An introduction to large language models, prompting and large language model app design, covering, with no prerequesites, the core concepts required to build applications on top of large language models.
Large Language Models
A large language model is a deep-learning system (generally based on the Transformer architecture) capable of generating text. Large language models operate on tokens which represent words or parts of a word (tokenization is a bijection between text and lists of tokens required by the transformer architecture). They are trained over internet-scale datasets (CommonCrawl, StackOverflow, Github, ...) to predict the next token given a list of tokens passed as input.
Given some text as input, called the prompt, a large language model will generate a likely completion based on its training data. It can simply be seen as a massive auto-complete system trained at Internet-scale.
To generate text from a large language model, we use what is referred to as auto-regressive
decoding. Given a prompt, we use the model to predict the next token. Once this token is
predicted we append it to the current prompt and reiterate the same process until the model emits a
special <|EndofText|> token or runs out of context.
Context Size
To predict the next token, Transformer-based large language models will attend (look at all previous tokens, the prompt) with a process called Attention. This computationally expensive process imposes constraints on the maximum amount of text a model can operate with. This maximum length is referred to as its context size. Each large language model has a specific context size, but it generally consists of 4000 tokens (~4000 words). Some have 2000, others have up to 8000.
When working with a large language model, context size is one of the main limiting factors, as it bounds the amount of information you can use to condition the prediction of the model.
Prompting
If you want to get a model to continue an article, you'll generally use the beginning of the article as prompt, providing amply enough signal for the model to understand that you're interested in generating the rest of the article. But let's say you want to translate a piece of English text to French? How would encode for the model the fact that you want your sentence translated?
For models that are solely trained on data extracted from the Internet, the best technique to encode
which task you're interested in is to use few-shot prompting. Few-shot prompting consists in
showing to the model a few examples of the task you're interested in as a way to encode that task.
As an example, the following prompt will successfully lead to your <YOUR SENTENCE> being
translated in French:
EN: Good Morning.
FR: Bonjour.
EN: The car is blue.
FR: La voiture est bleue.
EN: <YOUR SENTENCE>
FR:
Note that the examples we provide to the model do not serve as training data (translation being an emerging capability of large language models that is acquired during training), but instead solely serve as a way to encode the task we care about. We say that large language models are few-shot learners; they are capable of understanding a task with just a few examples.
Few-shot prompting, consisting in presenting a few examples of a task, is an effective way to encode to models the task you care about.
Intuitively, if you had read and somewhat memorized the entire Internet, and were tasked to generate the most likely completion to the prompt above, similarly to the model you would likely decide that the correct continuation is a translation of the last sentence. Large language models work in basically the same way. And in many aspects, being trained on human-generated data, they often appear as surprisingly anthropomorphic.
Instruction-following
Now assume you would like to summarize a somewhat long piece of text. You are faced with a new problem, as providing a few examples of the task might consume too much of your limited context size. Instead you could try to provide instructions to the model:
<LONG TEXT>
Generate a 1-paragraph summary of the text above:
While a good idea, for models that were solely trained on data from the Internet, this approach is in practice quite brittle compared to few-shot prompting. Documents seldom appear on the Internet with instructions, followed by the result of applying these instructions. Its not impossible but not common, hence the reason why it works at times but remains brittle. A naive use of instructions on such models will often lead to the model ignoring the instructions (maybe assuming it was text from an ad) or failing to properly apply them.
Instruction-following models alleviate the need for few-shot prompting.
To solve this issue, large language models can be fine-tuned (trained for a bit longer on top of their initial training) for instruction-following. Various techniques exist for this process, but the important part is that the resulting model is biased towards following instructions, rendering viable the approach described above.
Along with a well thought-out UI, improvements in instruction-following was one of the core advances of ChatGPT, possibly explaining its rapid success. ChatGPT relied on a novel instruction-following fine-tuning paradigm called reinforcement learning from human feedback.
Fine-tuning
Another way to encode a task or teach the model new information is to use fine-tuning. Since it involves training, fine-tuning will drastically alter the distribution (the actual behavior) of your model.
Let's say you have a database of hundreds of thousands of customer support interactions in the form
of (question, answer) pairs. To construct a customer-support bot, you could fine-tune a model on
the following distribution (or dataset, the two can be used interchangeably as a dataset represents
a distribution):
Q: <QUESTION>
A: <ANSWER>
<|EndOfText|>
Anytime a question would need answering, you could provide the following prompt to the fine-tuned model:
Q: <QUESTION>
A:
... and expect to get a useful answer. Given that this dataset contains a lot of information about your company or products, in order to be able to accurately predict each token (which is the fine-tuning or training objective), the model would have to memoize that information. Additionally, the task would be encoded in the new distribution of the model, and instruction-following or few-show prompting would not be required anymore.
Caveats. This looks ideal but there are a few caveats to keep in mind with with fine-tuning. First, given the size of typical models, a lot of data is needed for fine-tuning to work well in practice (think 10m-100m words). Additionally, it is unclear—and still an open research question—how much fine-tuning brain-damages the model, rendering it less smart. Finally, one has to be careful about exactly how they encode the task. As an example, if the date of the question is not shown to the model in the examples above, the model might consider deprecated information as still relevant and answer erroneously, or maybe learn spurious statistical relationships between the type of question and the tone of the answer.
Fine-tuning is an incredibly powerful mechanism. But it is important to remember that it entangles the process of encoding a task and teaching new information to the model. The latter possibly leading to surprising or unexpected results.
Embedding models
These models are trained to embed text into a vector space. Their input is a piece of text and their output is a high-dimensional vector of floats (hundreds to thousands). The resulting embeddings represent the associated text semantically and can be used to perform search.
Modern embedding models are based on the same Transformer architecture. Therefore, they also have a limited context size. They are generally trained, on similar datasets as large language models, by Contrastive learning. Contrastive learning consists in decreasing the angle of (or rapproaching) vectors resulting from the embeddings of pieces of text that are related (as an example, originated from the same document), and increasing the angle of (or separating) vectors resulting from the embeddings of pieces of unrelated text.
Given some text as input, an embedding model will generate a vector representation of the text that can be used to perform semantic search.
Embeddings generated by the trained model can be used to perform semantic search. Take a collection of documents. For each document, cut it in chunks that fit in the context size of the model. For each resulting chunk, generate an embedding. Now, given a query, generate an embedding of the query. The chunks whose vectors are the closest to the query's vector are likely to be the most sematically relevant to the query. The power of this approach is that it works even if different words are used to discuss the same concept (for example "dog" and "canine").
The process of retrieving highly similar vectors and their associated chunks given a query (and its vector) is called (embedding) vector search or semantic search.
See Data Sources to learn more about how Dust provides fully-managed solutions to automatically embed documents and perform vector search on the resulting database.
Large Language Model Apps
A large language model app is a chain of one or multiple prompted calls to models or external services (such as APIs or Data Sources) designed to perform a particular task. Said otherwise, a large language model app is an orchestration layer that sits on top of a model in order to specialize its behavior to perform a specific task.
A large language model app is a chain of one or multiple prompted calls to models or external services (such as APIs or Data Sources) in order to achieve a particular task.
As an example, the translation prompt above which consists in data (the few-shot examples), a template (the way these examples are presented to the model), reified as a function that, given a sentence, returns the output of the model, can be seen as a basic large language model app.
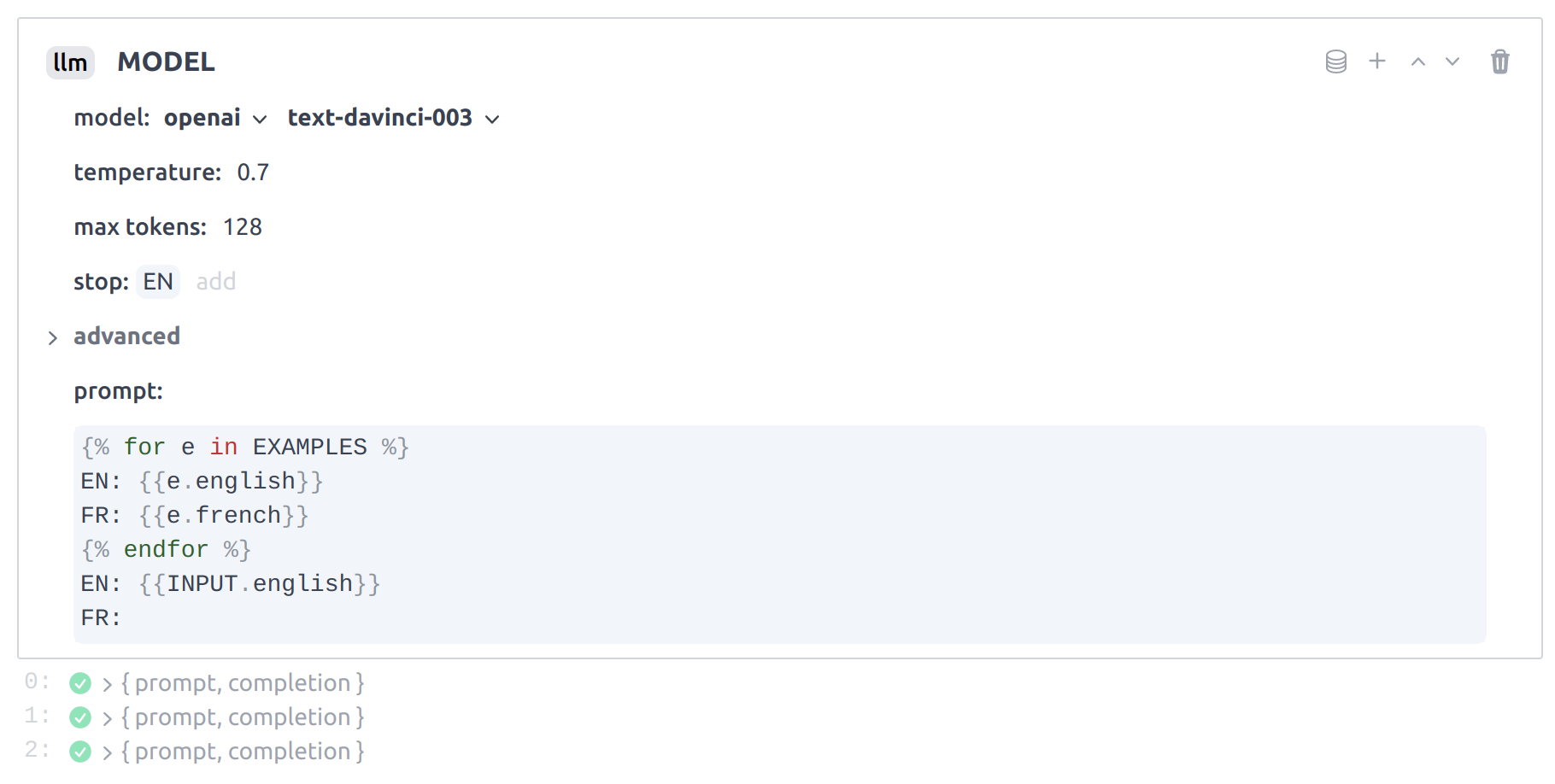
Example of a Dust LLM block representing the call to a Large Language Model. Dust apps are chains of such blocks. You'll learn more about Dust apps and blocks in the Platform overview.
The design of a large language model app is the process of defining prompts and chains of large language models or external services calls to expose a structured API with a predictable behavior built on top of large language models' generic interface. The purpose of Dust is to help design and deploy such large language model apps.
In the rest of this document, we'll present three examples of large language model apps of increasing complexity with links to their implementation in Dust.
(Easy) Translation
As seen above, translation is a simple task that can be encoded using a few-shot prompt. A large language model app for translation therefore mostly consists in one parametrized call to a large language model. In Dust, this is achievable with the following blocks (most of these blocks are described in greater details the following pages):
- An
inputblock to receive the text to translate (see Inputs). - A
datablock that returns the few-shot examples maintained in a dataset (see Datasets). - An
llmblock that parametrizes the call to the large language model (see TODO(spolu)). - A
codeblock to process the output of the large language model (see TODO(spolu)).
The llm block main parameter is the prompt. The prompt is a templated string that will be
constructed from the data block and the input block. The template we use for this app is the
following:
{% for e in EXAMPLES %}
EN: {{e.english}}
FR: {{e.french}}
{% endfor %}
EN: {{INPUT.english}}
FR:
The templating language used by llm blocks is based on the Tera
engine, similar to Jinja2. The llm block will construct the prompt by replacing the
{{e.english}}, {{e.french}} and {{INPUT.english}} placeholders with the actual data returned
by the data block (called EXAMPLES here) and the input block (called INPUT here). Note the
use of a loop to iterate over the examples (lines 1 and 4).
You can find and explore the full implementation of this app in Dust here:
intro-translation. In particular you can introspect the
prompt sent to the model and the completion it returned by clicking on the outputs of the llm
block.
(Medium) Recursive Summarization
Recursive summarization consists in summarizing a piece of text that is too long to hold in the context of the large language model. The technique consists in splitting the text in chunks and summarizing each chunk separately. The output of the summarization of each chunk is then concatenated and used to produce a final summary.
If the text to summarize is extremely long, this process can be repeated recursively until the concatenation of the chunks fit in-context. Hence the name recursive summarization.
To summarize each chunk as well as produce the final summary we can use a model fine-tuned for
instruction-following such as OpenAI's text-davinci-003.
For each chunk we can use the following prompt to obtain a summary:
{{CHUNK}}
Summarize the paragraphs above in under 512 characters.
SUMMARY:
To obtain the final summary the following prompt has been demonstrated to work well:
TITLE: {{INPUT.title}}
AUTHOR: {{INPUT.author}}
CONTENT: {{AGGREGATE.blob}}
Summarize the text above in one ~1000 characters paragraph, not repeating the title or author.
SUMMARY:
These two prompts are just examples of how to encode the task of summarization to an instruct-following model. They can likely be improved or modified to produce specific results.
The Dust app that demonstrates this technique leverages blocks such as map and reduce that will
be more clearly explained in the following pages. You can find and explore its full implementation
here: recursive-summarization.